ディープラーニングの学習ってどういう事だろう?そんな話です。
学習の過程
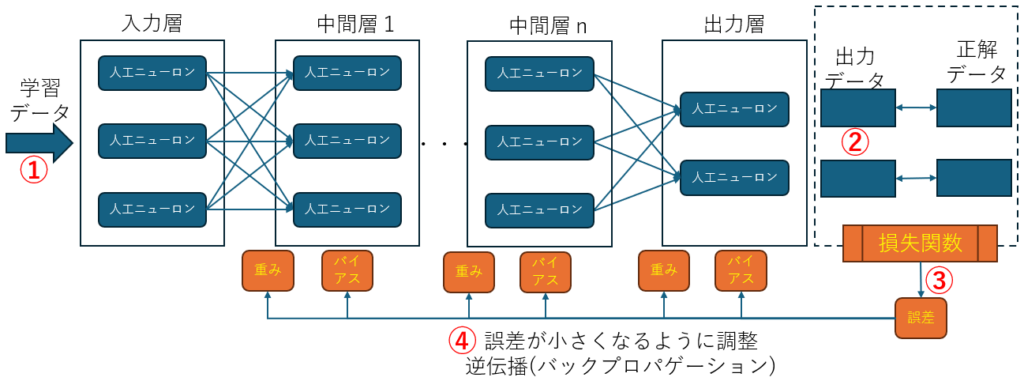
学習の過程はこの繰り返しです
① 学習データの投入
② 推論を実行
③ 損失関数を使って結果を正解データと比較し誤差を得る
④ 誤差が小さくなるように重みを更新する
ここで、重みとバイアスの初期値はいずれも乱数によるランダム値です。この、重みとバイアスを正解が出力されるように調整する、という事が学習になります。
重みとバイアスがどうなれば正しい結果が得られるのか、論理的な説明は有りません。以前、ある自動車メーカーから製造ラインで使用するシステムの相談を受けたことが有りますが、ニューラルネットワークでは何故その結果が出るのか説明しずらいので使いづらい、という様な事を言われた記憶が有ります。
また、よく「パラメータ数」という言い方が有ります。この「パラメータ数」は「重み」と「バイアス」の総数になり、GPT3で1750億パラメータ、GPT4で数百億~1兆程度有ると言われています。
損失関数
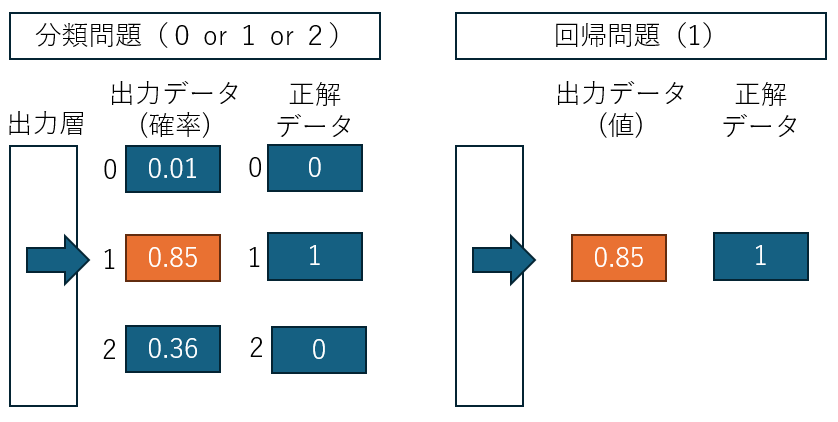
分類問題(どれなのか?)の場合、出力ニューロンは取りうる出力値の数だけあり、確率的に最も高いニューロンが正解と判断され、回帰問題(いくつなのか?)の場合、出力ニューロンは1つでこの値を正解とします。
そして、全ての学習データで正解に近づく様に重みとバイアスが調整されるのが学習という事になります。
分類問題では「交差エントロピー誤差」、が、回帰問題では「二乗和誤差」が主に使われます。
分類問題で正解データが0か1なのは、「One-Hot表現」と言って、予め準備しておくものです。
逆伝播について、数百億~1兆程度の多変数パラメータをどうやって計算するんだ?という話が有りますがそこは数学的に色々手法が有るみたいです。次回まで。
2024年11月13日 手塚幹人
コメント